合規與資料主權:跨國企業能用DeepSeek V4嗎?

目錄
共 10 個章節
合規與資料主權:跨國企業能用DeepSeek V4 嗎?
2026 年 4 月 24 日,中國 AI 企業深度求索(DeepSeek)正式發布新一代大模型 DeepSeek V4 預覽版本,分為 Pro(1.6T 總參數、49B 激活)與 Flash(284B 總參數、13B 激活)兩個版本,均支援 1M token 上下文,並採用 MIT 授權開放權重。這項消息迅速引爆產業界,華為同日宣布 Ascend 950 超節點原生支援 V4,中芯國際(SMIC)港股當天急升 9%。然而,對於跨國企業——尤其是金融、醫療、法律等高度監管行業——真正關心的不是模型跑多快,而是:「我的資料會落到誰手上?」
當美國聯邦眾院在 2025 年 4 月公布的調查報告指控 DeepSeek「透過美國基礎設施的後端搬運用戶數據」,並指出「在 85% 回覆內容中修改或抑制政治敏感題目」時,資料主權與合規問題已從技術討論升級為地緣政治風險。本文將深入剖析 DeepSeek V4 在跨國場景中的適用邊界,並提出一條 MIT 授權下的本地部署替代路徑,幫助企業在效率與風險之間做出明智抉擇。
一、DeepSeek V4 的技術亮點與開源策略
根據官方發布資訊,DeepSeek V4 的核心突破在於「百萬級上下文能力」與「全棧國產算力適配」。Pro 版本採用 MoE(Mixture of Experts)架構,總參數達 1.6T,但每次推理僅激活 49B 參數,大幅降低計算開銷;Flash 版本則主打輕量化,總參數 284B、激活 13B,適合高頻 Agent 流量。兩者均支援 1M token 的上下文窗口,這在當前開源模型中屬於頂尖水準。
更值得關注的是其開源策略。DeepSeek V4 全程採用 MIT 授權,分階段開放模型權重,同時相容 OpenAI SDK——開發者只需改個 endpoint 就能從其他 API 遷移過來。這項設計大幅降低了轉換成本,讓中小企業、研究機構甚至個人開發者都能參與生態。在閉源模型 token 費用持續上漲的今天,這種「技術平權」姿態確實獲得社群高度期待。
但「開源」不等於「零風險」。MIT 授權允許任何人下載、修改、商用模型權重,但前提是使用者必須自行負責數據處理與部署環境。當企業透過 DeepSeek 官方 API 調用模型時,提示詞、商業機密、客戶資料全數傳送到中國伺服器,這便觸發了跨境資料傳輸的合規開關。因此,開源本身只是工具,真正的合規關鍵在於部署方式。
二、合規風險全景:從美國國會調查到亞洲法規
自2025年4月美國聯邦眾院「中國特別委員會」發布調查報告以來,後續調查持續升級。2026年4月底,眾院國土安全委員會與中國委員會更發起聯合調查,重申三大核心指控:DeepSeek 透過美國基礎設施的後端搬運用戶數據;在 85% 的回覆內容中修改或抑制被認為政治敏感的題目,且未向用戶揭露;以及其訓練數據可能存在合規疑慮。雖然這些指控仍處於調查階段,尚未有正式裁罰,但已對跨國企業的採購決策產生寒蟬效應。

將視角拉回亞洲。台灣方面,個人資料保護法要求個資跨境傳輸至境外處理需確認當地保護水準,若使用 DeepSeek 官方 API(伺服器位於中國),企業必須進行個資影響評估,並取得當事人明確同意。此外,AI 基本法(2025 年 12 月 23 日三讀通過,2026 年 1 月 14 日公布施行)建立框架,後續由數位發展部依此法推動 AI 風險分類框架,要求生成式 AI 服務進行風險分級與透明度標示,金融業更有金管會指引要求模型與資料須可稽核、可解釋。香港方面,個人資料(私隱)條例第 33 條雖尚未強制實施,但 PCPD 已發布 AI 個資保障指引,要求企業在使用 AI 前執行個人資料影響評估(PIA)。若涉及跨境資料流通至大灣區,則須遵循 GBA 標準合約。金管局的 GL-8 指引更要求金融機構建立模型風險管理框架。
換言之,若跨國企業選擇透過 DeepSeek 雲端 API 提供服務,幾乎必然觸發至少一個司法管轄區的合規要求。尤其是金融與醫療業——後者的病患資料往往受到更高規格的保護(如台灣的《人體生物資料庫管理條例》與美國 HIPAA 的域外效力),將數據送往中國伺服器的做法幾乎不可行。
三、資料主權挑戰:API 與本地部署的鴻溝
資料主權的核心問題在於:數據是否必須送往受中國法律管轄的伺服器?若使用 DeepSeek 官方 API,答案為「是」。根據中國《網絡安全法》與《數據安全法》,在中國境內運營的服務供應商有義務配合政府監管要求,包括提供用戶數據。美國國會調查報告中「後端搬運用戶數據」的指控,正是指向這種潛在的數據流向。
然而,DeepSeek V4 的 MIT 授權提供了另一條路徑:本地部署。企業可以下載模型權重(Pro 版 865 GB,Flash 版 160 GB),在自己的機房或雲端虛擬機上執行推論。所有資料、提示詞、輸出結果完全不離開企業可控的基礎設施。這等同於將資料主權完全歸還給企業自身。
當然,本地部署並非零成本。它需要高效能的硬體——Pro 版本建議至少一張 H100 或華為 Ascend 950 等級的 GPU,Flash 版本則在消費級顯示卡上就能量化部署(Ollama、vLLM 直接支援)。企業需自行負擔硬體採購、電力、散熱、運維工程師等人力成本。但一次性投資後,邊際成本趨近於零,不再擔心 API 漲價或被供應商鎖定。
以台灣金融業為例,若在本地機房部署 Flash 版本提供客服機器人,不僅符合金管會對模型可稽核性的要求,更可確保客戶資料(帳戶資訊、交易紀錄)完全留存在島內。類似的邏輯也適用於香港金融機構——地端自架 DeepSeek V4 可同時滿足 GL-8 與 GBA 標準合約的規範。
四、成本對比:API 定價 vs 本地部署 TCO
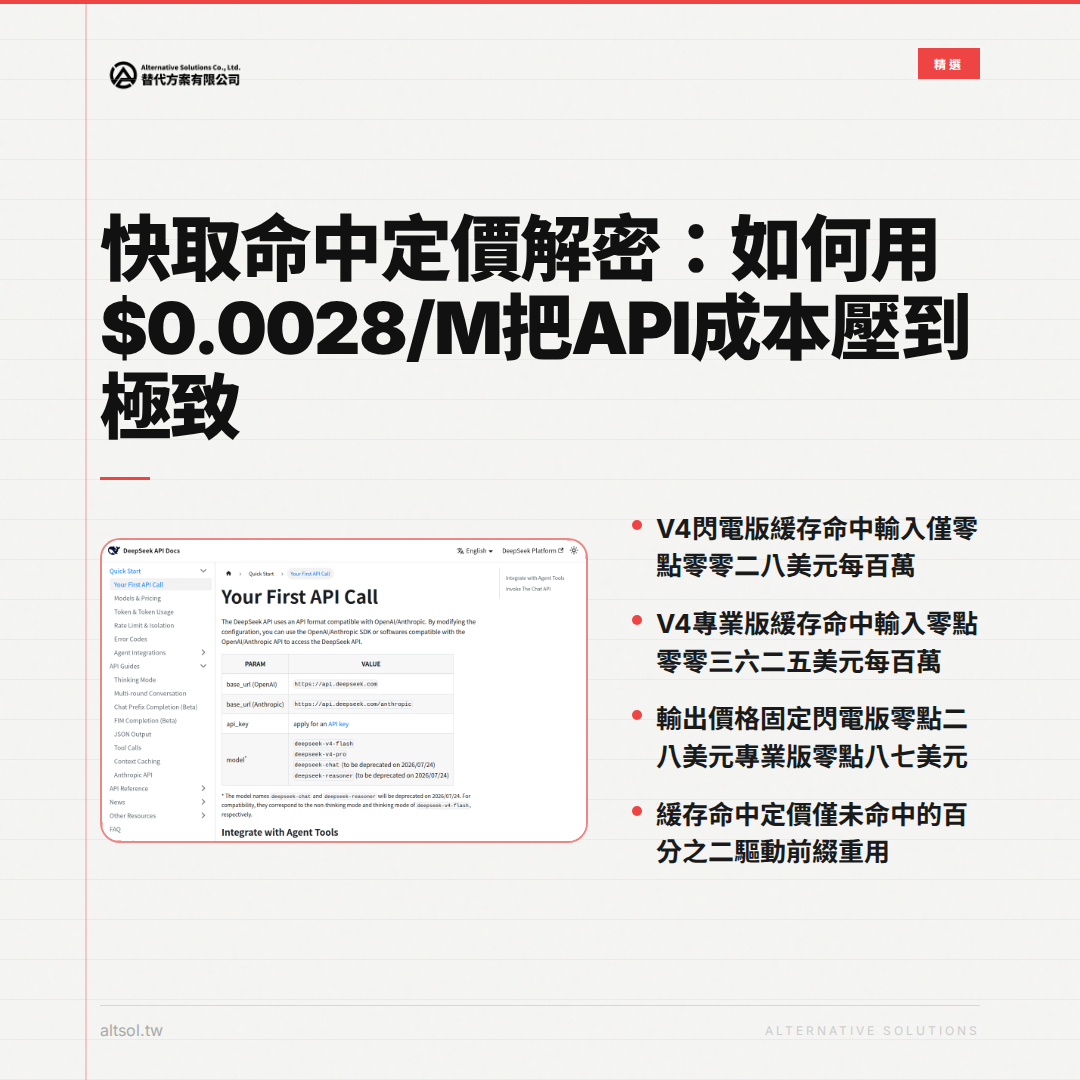
[LATEST DATA] 提供了官方 API 定價,我們將其整理為下表,並對比本地部署的成本結構。
| 模型 | 輸入(快取命中/百萬Token) | 輸入(快取未命中/百萬Token) | 輸出(百萬Token) | 適合場景 |
|---|---|---|---|---|
| DeepSeek V4 Flash | $0.0028 | $0.14 | $0.28 | 高頻 Agent 流量 |
| DeepSeek V4 Pro | $0.003625 | $0.435 | $0.87 | 複雜程式碼與推理 |
以每日處理 1 億 Token 的企業為例(包含輸入與輸出),若全部使用快取未命中價格,Flash 版本每日成本約 $14 + $28 = $42,Pro 版本約 $43.5 + $87 = $130.5。而本地部署的硬體成本:一台配備 8 張 H100 的伺服器約 $300,000,加上電力與維運,三年總成本約 $600,000 ~ $800,000。以 Flash 版本每日 $42 計算,約 20 年的 API 費用才等同於本地方案;因此,除非資料主權或法規要求,純從經濟角度來看,API 模式遠比本地部署划算。
更何況,API 模式還存在數據外洩風險、網路延遲(影響即時回饋體驗)、以及供應商鎖定等隱性成本。2025 年發生的「Claude 資料外洩事件」與「GPT 訓練數據訴訟」已讓許多企業心生警惕,轉而擁抱本地部署。
五、FAQ:合規與 DeepSeek V4 的常見疑問

Q1:如果我只使用 DeepSeek V4 的開源權重,在自己的伺服器上跑,還需要遵守個資法嗎?
A:是的。模型權重本身不包含個人資料,但當你將客戶資料輸入模型進行推理時,該資料的處理行為仍受各國個資法規範。只要你在台灣境內處理,就必須遵循《個人資料保護法》;在香港境內則遵循《個人資料(私隱)條例》。地端部署的好處是你能完全控制資料流向,但企業仍須做好內部資料治理與影響評估。
Q2:美國國會的調查報告是否代表 DeepSeek V4 已被認定違法?
A:目前僅為調查報告,尚未形成最終裁罰或禁令。但報告中指出的「後端搬運數據」與「修改政治敏感內容」已構成重大風險提示。跨國企業在進行供應商盡職調查時,應將這些指控納入評分。建議在最終判決出爐前,優先選擇本地部署模式以隔離風險。
Q3:MIT 授權與其他開源授權(如 Apache 2.0)在合規上有何不同?
A:MIT 授權非常寬鬆,允許商用、修改、再發布,僅需保留原始版權聲明。它不要求專利授權,也不要求衍生作品必須開源。對於企業來說,MIT 授權是風險最低的開源授權之一,因為你不會因使用 DeepSeek V4 而被迫揭露自己的商業機密。
Q4:金融業使用 DeepSeek V4 本地部署時,需要做哪些額外準備?
A:根據金管會指引與香港 GL-8,你需要建立模型風險管理框架,包括:模型溯源記錄(從訓練資料到權重版本)、可解釋性報告(了解模型為何輸出特定結果)、以及定期稽核機制。此外,建議搭配內容過濾器,防止模型輸出違反監管規定的建議。這些都可以在本地部署環境中自主實現。
Q5:DeepSeek V4 的「國產硬體適配」是否強制要求使用中國晶片?
A:並非強制。適配代表模型已針對華為 Ascend 950等國產硬體進行算子優化,但你也可以使用 NVIDIA GPU(H100、A100)甚至消費級顯示卡。Flash 版本可在 Ollama 上量化部署,消費級 GPU 也能運行。企業應根據現有硬體基礎選擇,不需為了支援國產晶片而額外投資。
六、實際範例:金融業地端部署 DeepSeek V4 Flash 客服機器人
情境:台灣某銀行為加速客服效率,希望導入 AI 助理處理帳戶查詢、交易異常、信用卡爭議等常見問題。但客戶資料(身分證號、餘額、交易明細)屬於高度敏感個資,不得外洩至公有雲。
硬體配置:一台搭載 4 張 NVIDIA RTX 6000 Ada(或 2 張 H100)的伺服器,安裝 Ollama 與 vLLM,下載 DeepSeek V4 Flash 權重(160 GB)。
部署步驟:
- 1. 使用 Ollama 載入模型:
ollama pull deepseek-v4-flash - 2. 啟動 OpenAI 相容 API:
ollama serve(預設監聽 localhost:11434) - 3. 修改銀行內部客服系統的 endpoint 至本地 IP,即可開始使用。
- 4. 搭配 RAG(檢索增強生成)將內部 FAQ 文件向量化儲存在本地資料庫,防止模型幻覺。
- 5. 建立審計日誌:記錄每次查詢的輸入與輸出,符合金管會「可稽核」要求。
結果:所有用戶資料停留在銀行機房,網路延遲低於 10ms,且每月 token 費用為零(一次性硬體投入)。該銀行僅需支付電費與維運人力,與原先使用 OpenAI API 每月約 $200,000 的費用相比,大幅節省。
七、替代方案有限公司觀點
替代方案有限公司認為,DeepSeek V4 的 MIT 授權確實為跨國企業提供了一條合規的替代路徑,但企業不應盲目跟風。首先,本地部署的門檻不只在硬體,還在於模型運維能力——MoE 架構的排程、動態稀疏計算的監控、以及量化推理的精度取捨,都需要具備相應技術團隊。對於缺乏 AI 基礎設施經驗的企業,建議先從 Flash 版本起步,並透過 vLLM 的 Continuous Batching 特性最大化 GPU 利用率。
其次,地端部署雖然解決了資料主權問題,但無法迴避模型本身的政治敏感性過濾。根據美國國會調查,DeepSeek V4 在 85% 回覆中會修改或抑制政治敏感內容——即使權重在本地,模型內建的「安全閘門」仍可能影響輸出。金融業若需提供客觀的市場分析,可能需自行微調或使用 RAG 來稀釋偏見。替代方案有限公司建議,企業應在部署前進行至少 200 題隨機測試,評估模型在無審查狀態下的真實表現。
最後,比較 Gemma 4 與 DeepSeek V4 兩條開源路線:Gemma 4 由 Google 推出,同樣支援地端部署且已通過台灣個資法影響評估(GCP 台灣區域彰化資料中心),但 Gemma 4 的授權並非 MIT,而是自訂條款,在商用靈活度上略遜一籌。替代方案有限公司的架構評估顧問團隊可協助企業進行「合規衝擊矩陣」分析,釐清兩種模型在個資法、AI 基本法、金管會指引下的風險評分。

八、結論與行動呼籲
DeepSeek V4 的發布代表開源大模型進入百萬上下文、國產硬體適配的新紀元,其 MIT 授權更為跨國企業提供了「資料主權自主」的可能。然而,合規從來不是技術問題,而是政治與法律問題。若企業選擇雲端 API,必須面對美國國會調查持續發酵的風險,以及中國《網絡安全法》對數據跨境傳輸的潛在要求。若選擇本地部署,則需投入硬體與人力,卻能換取最完整的資料控制。
對於身處金融、醫療、政府等高度監管行業的讀者,我們建議:立即展開內部合規評估,確認現有 AI 供應鏈中是否涉及數據跨境傳輸。若發現風險,可從 DeepSeek V4 Flash 的本地部署 PoC 開始,驗證模型在自身場景下的表現。同時,持續關注 DeepSeek 官方論文中提及的「距離 GPT-5.4 與 Gemini-3.1-Pro 約 3 到 6 個月」的進展,為後續迭代保留升級空間。
資料主權不是一個可協商的選項,而是企業數位轉型的底線。選擇權就在你手中。